commit dd321acddc upstream.
When host_sleep_config command fails we should return error to
MMC core to indicate the failure for our device.
The misspelled variable is also removed as it's redundant.
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aee77e4acc upstream.
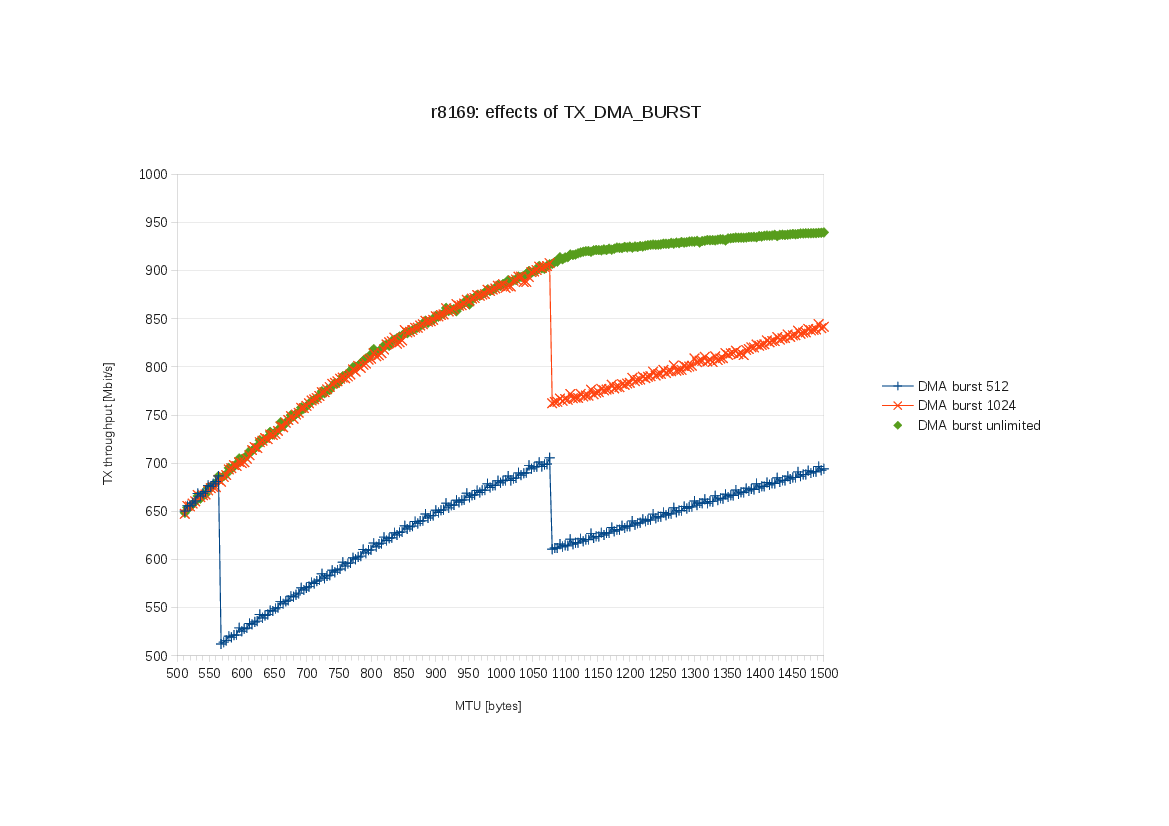
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 39707c2a3b ]
Driver anchors the tx urbs and defers the urb submission if
a transmit request comes when the interface is suspended.
Anchoring urb increments the urb reference count. These
deferred urbs are later accessed by calling usb_get_from_anchor()
for submission during interface resume. usb_get_from_anchor()
unanchors the urb but urb reference count remains same.
This causes the urb reference count to remain non-zero
after usb_free_urb() gets called and urb never gets freed.
Hence call usb_put_urb() after anchoring the urb to properly
balance the reference count for these deferred urbs. Also,
unanchor these deferred urbs during disconnect, to free them
up.
Signed-off-by: Hemant Kumar <hemantk@codeaurora.org>
Acked-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit bf7e1abe43 upstream.
Some hardware has correct (!= 0xff) value of tssi_bounds[4] in the
EEPROM, but step is equal to 0xff. This results on ridiculous delta
calculations and completely broke TX power settings.
Reported-and-tested-by: Pavel Lucik <pavel.lucik@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 8c6e30936a upstream.
bf->bf_next is only while buffers are chained as part of an A-MPDU
in the tx queue. When a tid queue is flushed (e.g. on tearing down
an aggregation session), frames can be enqueued again as normal
transmission, without bf_next being cleared. This can lead to the
old pointer being dereferenced again later.
This patch might fix crashes and "Failed to stop TX DMA!" messages.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ad1be8d345 upstream.
When register_netdev fails, the init'ed NAPIs by netif_napi_add must be
deleted with netif_napi_del, and also when driver unloads, it should
delete the NAPI before unregistering netdevice using unregister_netdev.
Signed-off-by: Devendra Naga <devendra.aaru@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 477206a018 upstream.
The r8169 may get stuck or show bad behaviour after activating TSO :
the net_device is not stopped when it has no more TX descriptors.
This problem comes from TX_BUFS_AVAIL which may reach -1 when all
transmit descriptors are in use. The patch simply tries to keep positive
values.
Tested with 8111d(onboard) on a D510MO, and with 8111e(onboard) on a
Zotac 890GXITX.
Signed-off-by: Julien Ducourthial <jducourt@free.fr>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 2a15cd2ff4 upstream.
With runtime PM, if the ethernet cable is disconnected, the device is
transitioned to D3 state to conserve energy. If the system is shutdown
in this state, any register accesses in rtl_shutdown are dropped on
the floor. As the device was programmed by .runtime_suspend() to wake
on link changes, it is thus brought back up as soon as the link recovers.
Resuming every suspended device through the driver core would slow things
down and it is not clear how many devices really need it now.
Original report and D0 transition patch by Sameer Nanda. Patch has been
changed to comply with advices by Rafael J. Wysocki and the PM folks.
Reported-by: Sameer Nanda <snanda@chromium.org>
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Cc: Rafael J. Wysocki <rjw@sisk.pl>
Cc: Hayes Wang <hayeswang@realtek.com>
Cc: Alan Stern <stern@rowland.harvard.edu>
Acked-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 811fd3010c upstream.
Realtek has specified that the post 8168c gigabit chips and the post
8105e fast ethernet chips recover automatically from a Rx FIFO overflow.
The driver does not need to clear the RxFIFOOver bit of IntrStatus and
it should rather avoid messing it.
The implementation deserves some explanation:
1. events outside of the intr_event bit mask are now ignored. It enforces
a no-processing policy for the events that either should not be there
or should be ignored.
2. RxFIFOOver was already ignored in rtl_cfg_infos[RTL_CFG_1] for the
whole 8168 line of chips with two exceptions:
- RTL_GIGA_MAC_VER_22 since b5ba6d12bd
("use RxFIFO overflow workaround for 8168c chipset.").
This one should now be correctly handled.
- RTL_GIGA_MAC_VER_11 (8168b) which requires a different Rx FIFO
overflow processing.
Though it does not conform to Realtek suggestion above, the updated
driver includes no change for RTL_GIGA_MAC_VER_12 and RTL_GIGA_MAC_VER_17.
Both are 8168b. RTL_GIGA_MAC_VER_12 is common and a bit old so I'd rather
wait for experimental evidence that the change suggested by Realtek really
helps or does not hurt in unexpected ways.
Removed case statements in rtl8169_interrupt are only 8168 relevant.
3. RxFIFOOver is masked for post 8105e 810x chips, namely the sole 8105e
(RTL_GIGA_MAC_VER_30) itself.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Cc: hayeswang <hayeswang@realtek.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Reviewed-by: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 10953db8e1 upstream
The link down would occur when reseting PHY. And it would take about 2 ~ 5
seconds from link down to link up. If the delay of pm_schedule_suspend is
not long enough, the device would enter runtime_suspend before link up.
After link up, the device would wake up and reset PHY again. Then, you
would find the driver keep in a loop of runtime_suspend and rumtime_resume.
Signed-off-by: Hayes Wang <hayeswang@realtek.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit deb9d93c89 upstream.
8168d and above allow jumbo frames beyond 8k. Bump the received
packet length check before enabling jumbo frames on these chipsets.
Frame length indication covers bits 0..13 of the first Rx descriptor
32 bits for the 8169 and 8168. I only have authoritative documentation
for the allowed use of the extra (13) bit with the 8169 and 8168c.
Realtek's drivers use the same mask for the 816x and the fast ethernet
only 810x.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Acked-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d58d46b5d8 upstream.
- fix features : jumbo frames and checksumming can not be used at the
same time.
- introduce hw_jumbo_{enable / disable} helpers. Their content has been
creatively extracted from Realtek's own drivers. As an illustration,
it would be nice to know how/if the MaxTxPacketSize register operates
when the device can work with a 9k jumbo frame as its documentation
(8168c) can not be applied beyond ~7k.
- rtl_tx_performance_tweak is moved forward. No change.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Acked-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit cf9ecf4b63 ]
On the earliest TSO capable devices, TSO was accomplished through
firmware. The TSO cannot coexist with ASF management firmware though.
The tg3 driver determines whether or not ASF is enabled by calling
tg3_get_eeprom_hw_cfg(), which checks a particular bit of NIC memory.
Commit dabc5c670d, entitled "tg3: Move
TSO_CAPABLE assignment", accidentally moved the code that determines
TSO capabilities earlier than the call to tg3_get_eeprom_hw_cfg(). As a
consequence, the driver was attempting to determine TSO capabilities
before it had all the data it needed to make the decision.
This patch fixes the problem by revisiting and reevaluating the decision
after tg3_get_eeprom_hw_cfg() is called.
Signed-off-by: Matt Carlson <mcarlson@broadcom.com>
Signed-off-by: Michael Chan <mchan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 2b018d57ff ]
When PPPOE is running over a virtual ethernet interface (e.g., a
bonding interface) and the user tries to delete the interface in case
the PPPOE state is ZOMBIE, the kernel will loop forever while
unregistering net_device for the reference count is not decreased to
zero which should have been done with dev_put().
Signed-off-by: Xiaodong Xu <stid.smth@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
{kind=link}