Add basic clang support in clang.cpp and test__clang() testcase. The
first testcase checks if builtin clang is able to generate LLVM IR.
tests/clang.c is a proxy. Real testcase resides in
utils/c++/clang-test.cpp in c++ and exports C interface to perf test
subsystem.
Test result:
$ perf test -v clang
51: builtin clang support :
51.1: Test builtin clang compile C source to IR :
--- start ---
test child forked, pid 13215
test child finished with 0
---- end ----
Test builtin clang support subtest 0: Ok
Committer note:
Make sure you've enabled CLANG and LLVM builtin support by setting
the LIBCLANGLLVM variable on the make command line, e.g.:
make LIBCLANGLLVM=1 O=/tmp/build/perf -C tools/perf install-bin
Otherwise you'll get this when trying to do the 'perf test' call above:
# perf test clang
51: builtin clang support : Skip (not compiled in)
#
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexei Starovoitov <ast@fb.com>
Cc: He Kuang <hekuang@huawei.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Joe Stringer <joe@ovn.org>
Cc: Zefan Li <lizefan@huawei.com>
Cc: pi3orama@163.com
Link: http://lkml.kernel.org/r/20161126070354.141764-11-wangnan0@huawei.com
[ Removed "Test" from descriptions, redundant and already removed from all the other entries ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Perf hooks allow hooking user code at perf events. They can be used for
manipulation of BPF maps, taking snapshot and reporting results. In this
patch two perf hook points are introduced: record_start and record_end.
To avoid buggy user actions, a SIGSEGV signal handler is introduced into
'perf record'. It turns off perf hook if it causes a segfault and report
an error to help debugging.
A test case for perf hook is introduced.
Test result:
$ ./buildperf/perf test -v hook
50: Test perf hooks :
--- start ---
test child forked, pid 10311
SIGSEGV is observed as expected, try to recover.
Fatal error (SEGFAULT) in perf hook 'test'
test child finished with 0
---- end ----
Test perf hooks: Ok
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Cc: Alexei Starovoitov <ast@fb.com>
Cc: He Kuang <hekuang@huawei.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Joe Stringer <joe@ovn.org>
Cc: Zefan Li <lizefan@huawei.com>
Cc: pi3orama@163.com
Link: http://lkml.kernel.org/r/20161126070354.141764-5-wangnan0@huawei.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This patch modifies the build dependencies on the jitdump support in
perf. As it stands jitdump was wrongfully made dependent 100% on using
DWARF. However, the dwarf dependency, only exist if generating the
source line table in genelf_debug.c. The rest of the support does not
need DWARF.
This patch removes the dependency on DWARF for the entire jitdump
support. It keeps it only for the genelf_debug.c support.
Signed-off-by: Maciej Debski <maciejd@google.com>
Reviewed-by: Stephane Eranian <eranian@google.com>
Cc: Anton Blanchard <anton@ozlabs.org>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1476356383-30100-3-git-send-email-eranian@google.com
Fixes: e12b202f8f ("perf jitdump: Build only on supported archs")
[ Make it build only if NO_LIBELF isn't defined, as jitdump.o will only be built in that case ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
I wanted to know the hottest path through a function and figured the
branch-stack (LBR) information should be able to help out with that.
The below uses the branch-stack to create basic blocks and generate
statistics from them.
from to branch_i
* ----> *
|
| block
v
* ----> *
from to branch_i+1
The blocks are broken down into non-overlapping ranges, while tracking
if the start of each range is an entry point and/or the end of a range
is a branch.
Each block iterates all ranges it covers (while splitting where required
to exactly match the block) and increments the 'coverage' count.
For the range including the branch we increment the taken counter, as
well as the pred counter if flags.predicted.
Using these number we can find if an instruction:
- had coverage; given by:
br->coverage / br->sym->max_coverage
This metric ensures each symbol has a 100% spot, which reflects the
observation that each symbol must have a most covered/hottest
block.
- is a branch target: br->is_target && br->start == add
- for targets, how much of a branch's coverages comes from it:
target->entry / branch->coverage
- is a branch: br->is_branch && br->end == addr
- for branches, how often it was taken:
br->taken / br->coverage
after all, all execution that didn't take the branch would have
incremented the coverage and continued onward to a later branch.
- for branches, how often it was predicted:
br->pred / br->taken
The coverage percentage is used to color the address and asm sections;
for low (<1%) coverage we use NORMAL (uncolored), indicating that these
instructions are not 'important'. For high coverage (>75%) we color the
address RED.
For each branch, we add an asm comment after the instruction with
information on how often it was taken and predicted.
Output looks like (sans color, which does loose a lot of the
information :/)
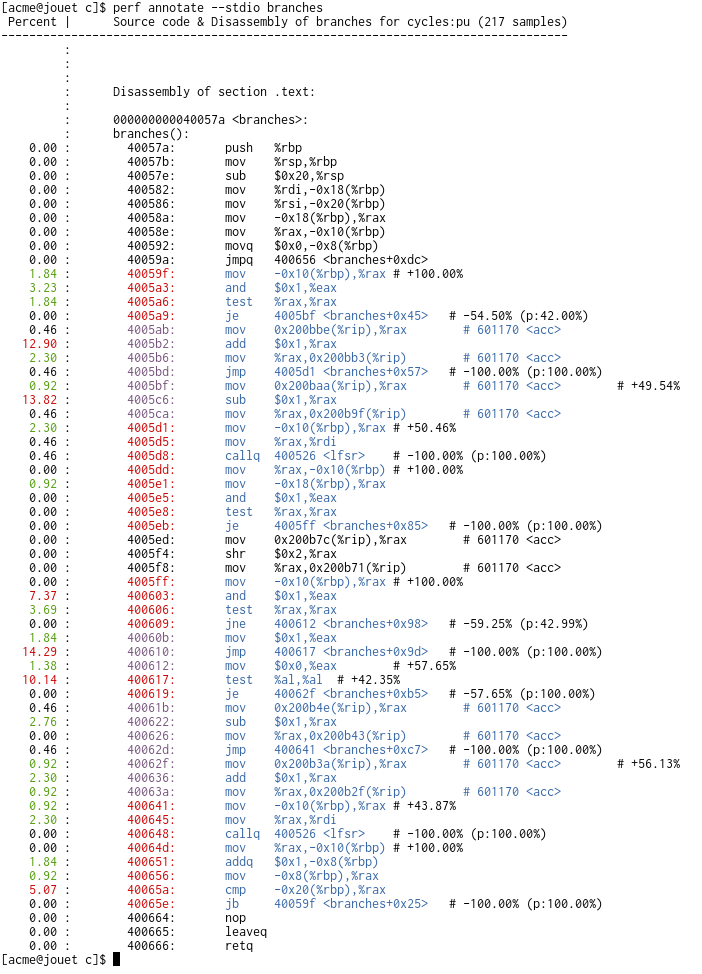
$ perf record --branch-filter u,any -e cycles:p ./branches 27
$ perf annotate branches
Percent | Source code & Disassembly of branches for cycles:pu (217 samples)
---------------------------------------------------------------------------------
: branches():
0.00 : 40057a: push %rbp
0.00 : 40057b: mov %rsp,%rbp
0.00 : 40057e: sub $0x20,%rsp
0.00 : 400582: mov %rdi,-0x18(%rbp)
0.00 : 400586: mov %rsi,-0x20(%rbp)
0.00 : 40058a: mov -0x18(%rbp),%rax
0.00 : 40058e: mov %rax,-0x10(%rbp)
0.00 : 400592: movq $0x0,-0x8(%rbp)
0.00 : 40059a: jmpq 400656 <branches+0xdc>
1.84 : 40059f: mov -0x10(%rbp),%rax # +100.00%
3.23 : 4005a3: and $0x1,%eax
1.84 : 4005a6: test %rax,%rax
0.00 : 4005a9: je 4005bf <branches+0x45> # -54.50% (p:42.00%)
0.46 : 4005ab: mov 0x200bbe(%rip),%rax # 601170 <acc>
12.90 : 4005b2: add $0x1,%rax
2.30 : 4005b6: mov %rax,0x200bb3(%rip) # 601170 <acc>
0.46 : 4005bd: jmp 4005d1 <branches+0x57> # -100.00% (p:100.00%)
0.92 : 4005bf: mov 0x200baa(%rip),%rax # 601170 <acc> # +49.54%
13.82 : 4005c6: sub $0x1,%rax
0.46 : 4005ca: mov %rax,0x200b9f(%rip) # 601170 <acc>
2.30 : 4005d1: mov -0x10(%rbp),%rax # +50.46%
0.46 : 4005d5: mov %rax,%rdi
0.46 : 4005d8: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 4005dd: mov %rax,-0x10(%rbp) # +100.00%
0.92 : 4005e1: mov -0x18(%rbp),%rax
0.00 : 4005e5: and $0x1,%eax
0.00 : 4005e8: test %rax,%rax
0.00 : 4005eb: je 4005ff <branches+0x85> # -100.00% (p:100.00%)
0.00 : 4005ed: mov 0x200b7c(%rip),%rax # 601170 <acc>
0.00 : 4005f4: shr $0x2,%rax
0.00 : 4005f8: mov %rax,0x200b71(%rip) # 601170 <acc>
0.00 : 4005ff: mov -0x10(%rbp),%rax # +100.00%
7.37 : 400603: and $0x1,%eax
3.69 : 400606: test %rax,%rax
0.00 : 400609: jne 400612 <branches+0x98> # -59.25% (p:42.99%)
1.84 : 40060b: mov $0x1,%eax
14.29 : 400610: jmp 400617 <branches+0x9d> # -100.00% (p:100.00%)
1.38 : 400612: mov $0x0,%eax # +57.65%
10.14 : 400617: test %al,%al # +42.35%
0.00 : 400619: je 40062f <branches+0xb5> # -57.65% (p:100.00%)
0.46 : 40061b: mov 0x200b4e(%rip),%rax # 601170 <acc>
2.76 : 400622: sub $0x1,%rax
0.00 : 400626: mov %rax,0x200b43(%rip) # 601170 <acc>
0.46 : 40062d: jmp 400641 <branches+0xc7> # -100.00% (p:100.00%)
0.92 : 40062f: mov 0x200b3a(%rip),%rax # 601170 <acc> # +56.13%
2.30 : 400636: add $0x1,%rax
0.92 : 40063a: mov %rax,0x200b2f(%rip) # 601170 <acc>
0.92 : 400641: mov -0x10(%rbp),%rax # +43.87%
2.30 : 400645: mov %rax,%rdi
0.00 : 400648: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 40064d: mov %rax,-0x10(%rbp) # +100.00%
1.84 : 400651: addq $0x1,-0x8(%rbp)
0.92 : 400656: mov -0x8(%rbp),%rax
5.07 : 40065a: cmp -0x20(%rbp),%rax
0.00 : 40065e: jb 40059f <branches+0x25> # -100.00% (p:100.00%)
0.00 : 400664: nop
0.00 : 400665: leaveq
0.00 : 400666: retq
(Note: the --branch-filter u,any was used to avoid spurious target and
branch points due to interrupts/faults, they show up as very small -/+
annotations on 'weird' locations)
Committer note:
Please take a look at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
To see the colors.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Anshuman Khandual <khandual@linux.vnet.ibm.com>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
[ Moved sym->max_coverage to 'struct annotate', aka symbol__annotate(sym) ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Support probing on offline cross-architecture binary by adding getting
the target machine arch from ELF and choose correct register string for
the machine.
Here is an example:
-----
$ perf probe --vmlinux=./vmlinux-arm --definition 'do_sys_open $params'
p:probe/do_sys_open do_sys_open+0 dfd=%r5:s32 filename=%r1:u32 flags=%r6:s32 mode=%r3:u16
-----
Here, we can get probe/do_sys_open from above and append it to to the target
machine's tracing/kprobe_events file in the tracefs mountput, usually
/sys/kernel/debug/tracing/kprobe_events (or /sys/kernel/tracing/kprobe_events).
Signed-off-by: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/147214229717.23638.6440579792548044658.stgit@devbox
[ Add definition for EM_AARCH64 to fix the build on at least centos 6, debian 7 & ubuntu 12.04.5 ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The tools so far have been using the strerror_r() GNU variant, that
returns a string, be it the buffer passed or something else.
But that, besides being tricky in cases where we expect that the
function using strerror_r() returns the error formatted in a provided
buffer (we have to check if it returned something else and copy that
instead), breaks the build on systems not using glibc, like Alpine
Linux, where musl libc is used.
So, introduce yet another wrapper, str_error_r(), that has the GNU
interface, but uses the portable XSI variant of strerror_r(), so that
users rest asured that the provided buffer is used and it is what is
returned.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-d4t42fnf48ytlk8rjxs822tf@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Move the call path handling code out of thread-stack.c and
thread-stack.h to allow other components that are not part of
thread-stack to create call paths.
Summary:
- Create call-path.c and call-path.h and add them to the build.
- Move all call path related code out of thread-stack.c and thread-stack.h
and into call-path.c and call-path.h.
- A small subset of structures and functions are now visible through
call-path.h, which is required for thread-stack.c to continue to
compile.
This change is a prerequisite for subsequent patches in this change set
and by itself contains no user-visible changes.
Signed-off-by: Chris Phlipot <cphlipot0@gmail.com>
Acked-by: Adrian Hunter <adrian.hunter@intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1461831551-12213-3-git-send-email-cphlipot0@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
We used libaudit to map ids to syscall names and vice-versa, but that
imposes a delay in supporting new syscalls, having to wait for libaudit
to get those new syscalls on its tables.
To remove that delay, for x86_64 initially, grab a copy of
arch/x86/entry/syscalls/syscall_64.tbl and use it to generate those
tables.
Syscalls currently not available in audit-libs:
# trace -e copy_file_range,membarrier,mlock2,pread64,pwrite64,timerfd_create,userfaultfd
Error: Invalid syscall copy_file_range, membarrier, mlock2, pread64, pwrite64, timerfd_create, userfaultfd
Hint: try 'perf list syscalls:sys_enter_*'
Hint: and: 'man syscalls'
#
With this patch:
# trace -e copy_file_range,membarrier,mlock2,pread64,pwrite64,timerfd_create,userfaultfd
8505.733 ( 0.010 ms): gnome-shell/2519 timerfd_create(flags: 524288) = 36
8506.688 ( 0.005 ms): gnome-shell/2519 timerfd_create(flags: 524288) = 40
30023.097 ( 0.025 ms): qemu-system-x8/24629 pwrite64(fd: 18, buf: 0x7f63ae382000, count: 4096, pos: 529592320) = 4096
31268.712 ( 0.028 ms): qemu-system-x8/24629 pwrite64(fd: 18, buf: 0x7f63afd8b000, count: 4096, pos: 2314133504) = 4096
31268.854 ( 0.016 ms): qemu-system-x8/24629 pwrite64(fd: 18, buf: 0x7f63afda2000, count: 4096, pos: 2314137600) = 4096
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-51xfjbxevdsucmnbc4ka5r88@git.kernel.org
[ Added make dep for 'prepare' in 'LIBPERF_IN', fix by Wang Nan to fix parallell build ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
We're using libaudit for doing name to id and id to syscall name
translations, but that makes 'perf trace' to have to wait for newer
libaudit versions supporting recently added syscalls, such as
"userfaultfd" at the time of this changeset.
We have all the information right there, in the kernel sources, so move
this code to a separate place, wrapped behind functions that will
progressively use the kernel source files to extract the syscall table
for use in 'perf trace'.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-i38opd09ow25mmyrvfwnbvkj@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
{kind=link}